This is the third post in our “Deep Dive into Terrajet” series. In Part 1 of the series, we discussed the Terrajet code generation pipelines that produce Crossplane managed resource definitions (Crossplane Resource Model compliant CRDs) from Terraform provider schemas and also how those pipelines and certain runtime behaviour are configured. In Part 2, we have detailed the generic Terraformed controller and the ExternalConnecter and the ExternalClient implementations that plug this controller into Crossplane’s managed reconciler. And in this concluding post of the series, we will delve into the details of how we set up Terraform workspaces and how we interact with the Terraform CLI.
Terraform Concepts
Before we detail how we interact with Terraform in Terrajet, we would like to discuss some related Terraform concepts to set the ground and how they relate to Terrajet. Let’s start with the notion of a Terraform configuration.
Terraform Configuration
A terraform configuration is written in the declarative Terraform language and specifies the desired state for a set of remote resources. A configuration is composed of blocks, which usually declare some type of a remote infrastructure like a Cloud provider resource, arguments and expressions. A block has a type, zero or more labels and a body that encompasses further nested blocks and arguments.

In Fig. 1, we see a resource configuration block with two labels: The first label specifies the resource type, mongodbatlas_project, and the second label specifies the block’s name, test. The actual project name is specified as an argument in the block’s body, example-project.
Terraform also supports an alternative configuration syntax, the JSON configuration syntax. The JSON syntax has the same expressive power as the native language and at runtime, when Terrajet generates a Terraform configuration describing the desired state of a remote resource, the generated configuration is in JSON syntax. This is a natural choice for Terrajet because we can use JSON tags on the corresponding Go struct field declarations both to prepare the payloads of Kubernetes APIServer requests, and to generate the Terraform configuration in JSON syntax. As discussed in Part 1 of the series, we use the jsoniter library which supports multiple tag keys for a single struct field (see Fig. 2), and we employ two codecs (parsers) each of which uses one of these tag keys during marshalling/unmarshalling.
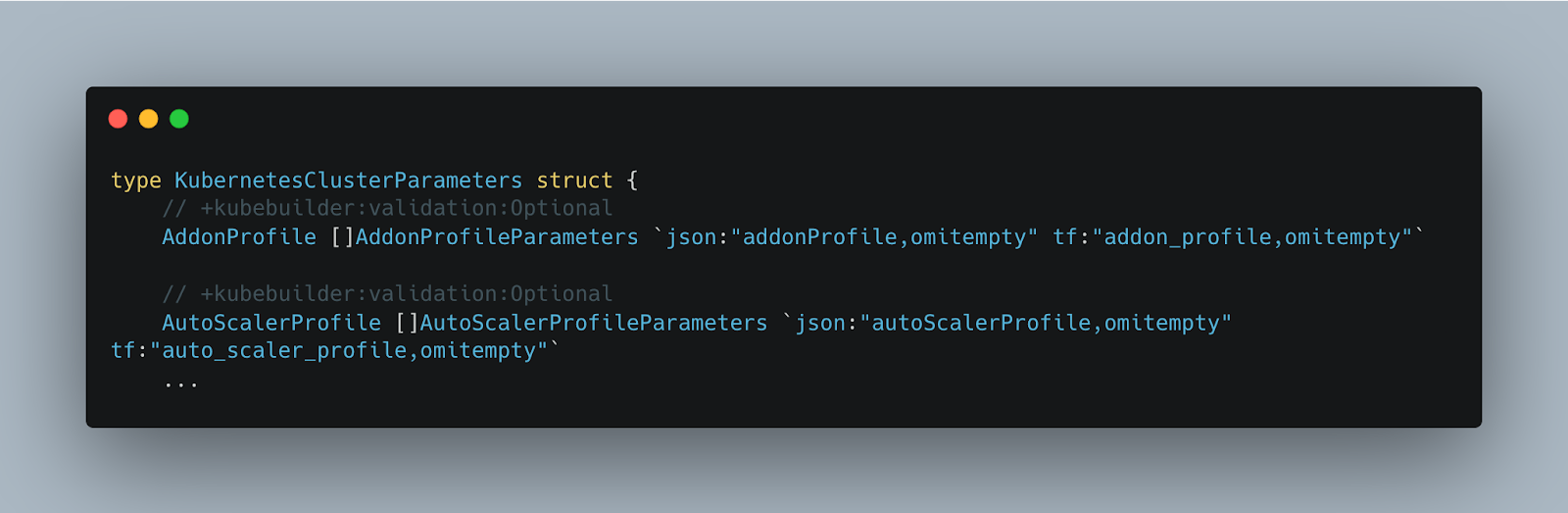
A JSON Terraform configuration generated by Terrajet contains the following 3 blocks:
Fig. 3 below shows an example configuration generated by Terrajet at runtime. Terrajet-generated configurations always contain a single provider configuration and no alternate provider configurations. Thus, the resource block always refers to the default provider configuration.
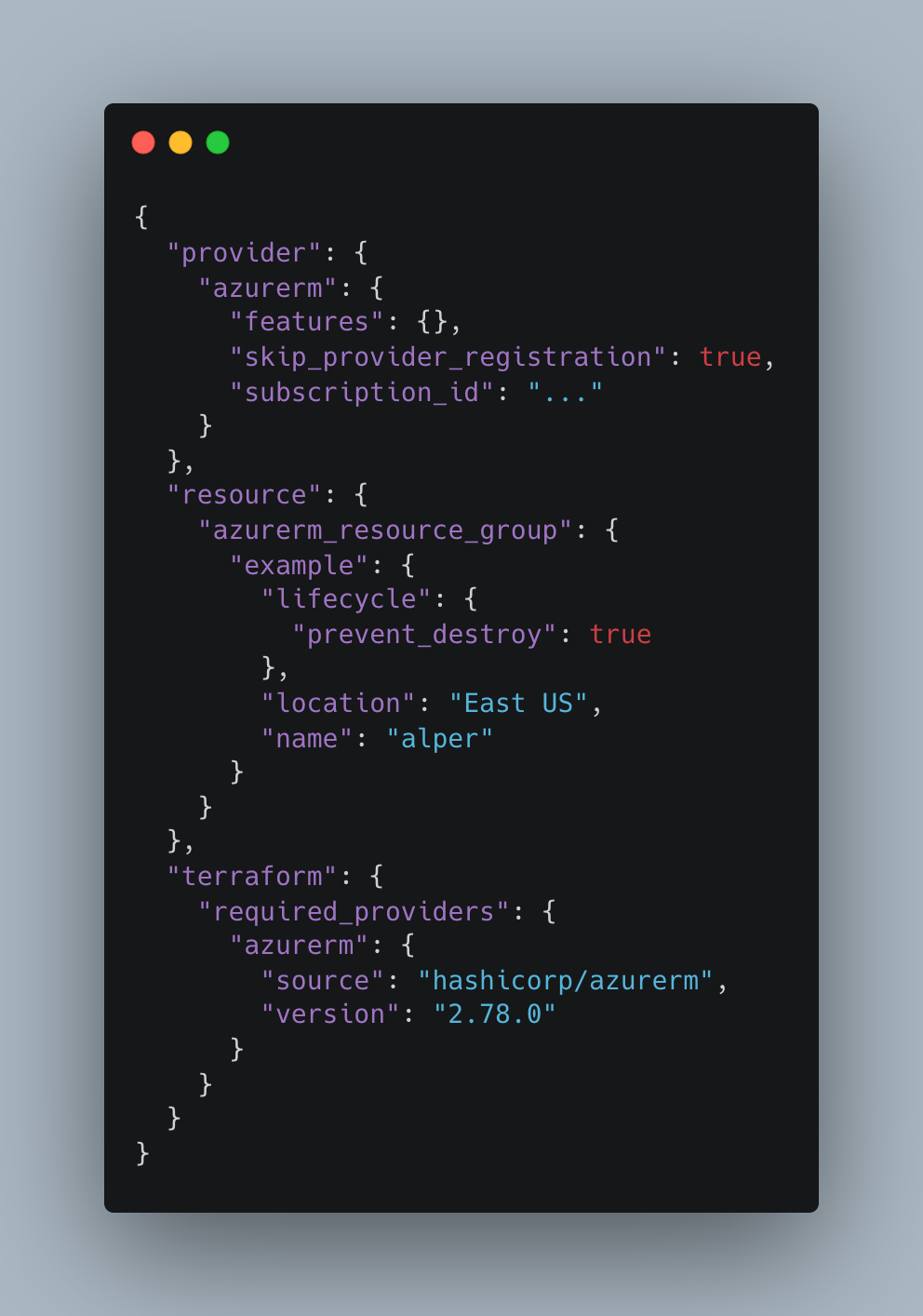
The provider block configures one single Terraform provider using the available Terrajet configuration. Terrajet allows configuration of a native Terraform provider via options provided in the terraform package, which we will talk about in detail later in this post.
The requirements block configures the requirements on the single configured provider, such as the required source and version of the native provider. While we are discussing the terraform package in this post, we will talk about how the native provider plugin is packaged and how Terrajet is configured to generate the correct native provider source and version here.
Finally, in the generated Terraform configuration, we have a single resource block. As discussed in the first post, Terrajet generates code that satisfies the resource.Terraformed interface for its managed resources. The Terraformed interface declares methods that allow Terrajet to generate the corresponding resource block for any Terraformed resource:
- metav1.GetName is called to name the Terraform resource in the configuration block with its Kubernetes metadata.name.
- Terrajet always adds the prevent_destroy lifecycle meta-argument to the resource block: Crossplane managed resources are not allowed to change their persistent IDs, i.e., you cannot destroy and recreate a piece of infrastructure corresponding to a managed resource without first deleting the Kubernetes managed resource object. However, Terraform handles certain configuration changes by first deleting the remote object and then recreating it with the new configuration. Terrajet guarantees this via the prevent_destroy meta-argument. Such configuration changes are to be blocked (made immutable) by Crossplane in the future.
- The resource block also specifies other arguments. We will detail how Terrajet generates these arguments in a moment.
Terraform State and Backends
State is a very central concept in Terraform. Terraform holds mappings from Cloud provider resources, such as a VM instance, to a configuration resource instance in the workspace’s state. State is used for various purposes in Terraform such as tracking resource dependencies or establishing a shared view of the remote resources managed by a configuration among distributed actors, but not all are relevant for Terrajet. For instance, tracking dependencies between resources is not relevant to us because in the Terrajet-generated configurations, we always have a single resource, one that corresponds to the managed resource in Kubernetes.
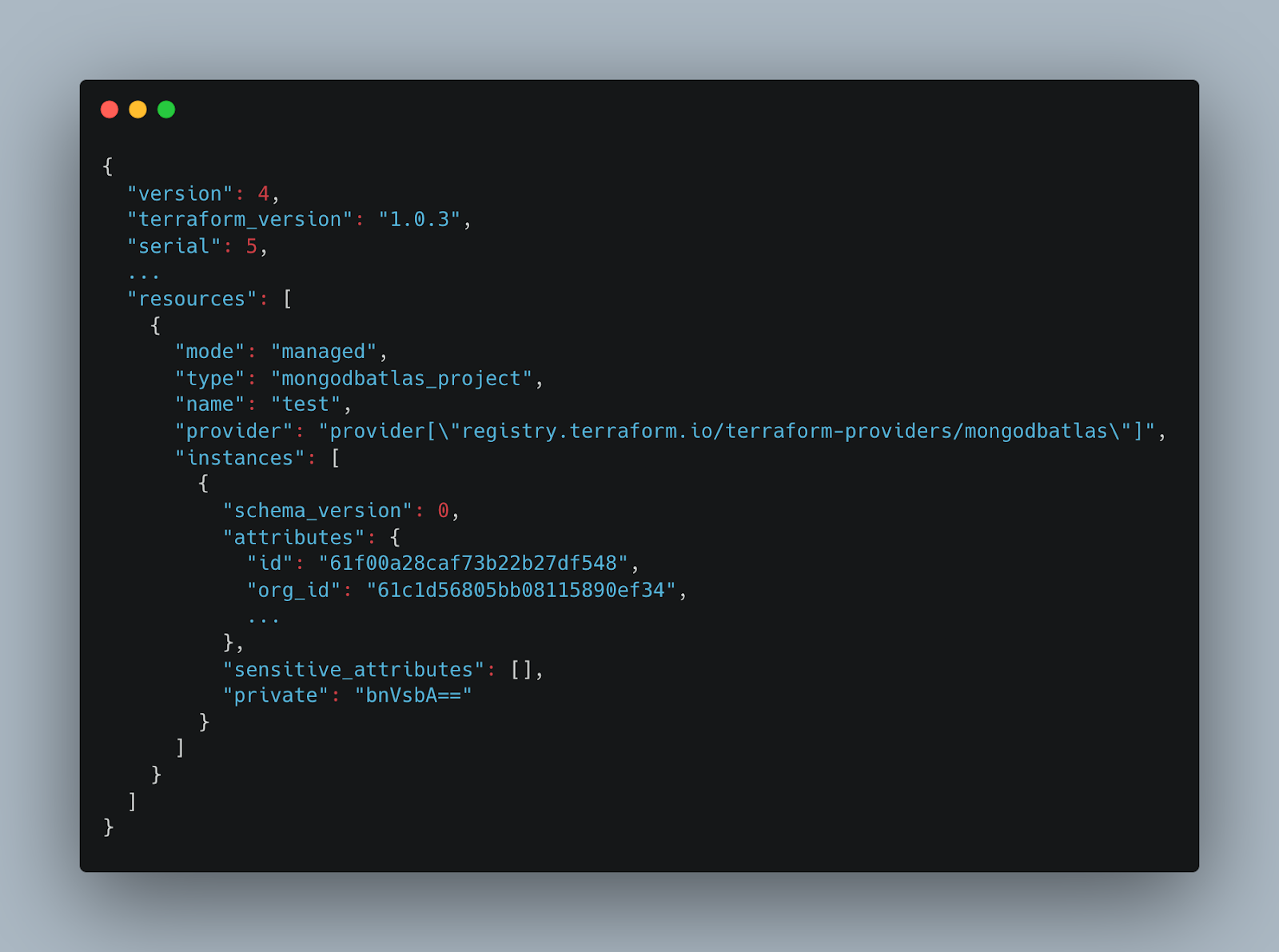
Terraform associates Cloud provider (aka remote) resources to configuration resources using their persistent identifiers. In Fig. 4, we see a terraform.tfstate file which maps the mongodbatlas_project configuration resource named test to the remote resource in the MongoDB Atlas Cloud Database Service with ID 61f00a28caf73b22b27df548. This identifier uniquely determines the MongoDB Atlas Project in the service.
Terraform has many backend implementations to store these state snapshots, such as Kubernetes, AzureRM, GCS, S3, or local. The backend to be used can be specified in the Terraform configuration, and in Terrajet, we currently use the default local backend. As the name implies, the local backend stores the Terraform state on the local filesystem.
A Terrajet-based provider’s local filesystem is an ephemeral resource, meaning that when its Kubernetes pod is destroyed, so are the state files being managed by that provider. When the provider reconciles for a Terraformed resource, it needs to be able to reconstruct the state for reasons discussed here. Also, the state can potentially contain sensitive data that should not be part of the spec or status of a managed resource. As we will detail while discussing the terraform package, Terrajet makes use of etcd as a means of persistent storage and distributes and recompiles state data to and from various Kubernetes objects at runtime while preparing the workspace.
Terraform CLI Workspaces
The Terraform state data stored in a backend is associated with a workspace. Certain backends like the local backend support multiple named workspaces through which you can manage multiple instances of a single Terraform configuration. Terrajet just makes use of the default workspace. As we will detail later while discussing packaging, it’s a low cost operation for Terrajet runtime to establish a unique workspace corresponding to a Terraformed resource. For each Terraformed resource, Terrajet uses the resource’s metadata.uid to name its workspace folder under the system’s temp folder and establishes a corresponding Terraform workspace with its configuration and state. The Workspace struct abstracts Terraform apply, plan, destroy operations on a workspace established by the Terrajet runtime.
Having discussed some core Terraform concepts with an overview of how they relate to Terrajet, let’s delve into the mechanics of:
- How the Terrajet runtime manages the lifecycles of multiple Terraform workspaces
- How these workspaces are constructed, i.e., how the main configuration file and the state file are generated at runtime for a specific Terraformed resource
- How the generic Terraformed managed.ExternalClient interacts with the terraform.Workspace to carry on the CRUD operations on remote infrastructure (for controller-side details of this topic, refer to Part 2 of the series)
- How the Terraform provider plugin binaries are packaged and the environment in which the Terraform CLI is run.
The terraform package
The Terrajet runtime is responsible for managing multiple Terraform workspaces, each corresponding to a single managed resource, simultaneously. What’s more, it does not rely on persistent volumes or special Terraform backends to persist state snapshots in these workspaces. In the following sections, we will detail the lifecycles of Terrajet-managed workspaces and how Terrajet runs the Terraform CLI to interact with the remote resources.
Workspace Lifecycle and the WorkspaceStore struct
The central abstraction around Terrajet’s workspace lifecycle management is the terraform.WorkspaceStore struct. WorkspaceStore implements two interfaces:
As discussed in Part 2 of this series, controller.Store’s Workspace method is invoked by the generic Terraformed ExternalConnecter to establish a Terraform workspace for the managed resource being reconciled at the beginning of each reconciliation loop. The workspace folder name is unique for a managed resource because WorkspaceStore uses the Terraformed resource’s metadata.uid to name it. And for initializing the Terraform workspace folder just created, WorkspaceStore uses a terraform.FileProducer to generate the state file if the state snapshot does not yet exist in the workspace, and the main configuration file in JSON syntax.
The final step in initializing the workspace folder is running a terraform init to install the provider plugin and to produce the dependency lock file, again if a lock file does not already exist. Subsequent reconciliations do not generate the state snapshot or run terraform init as they will be running on an already initialized workspace folder. However, if the workspace folder is for some reason destroyed, such as when the provider container is restarted, then WorkspaceStore will use the FileProducer to reproduce the state snapshot and will run terraform init to reproduce the dependency lock.
As we will revisit when we are discussing how we package Terrajet-based providers, the terraform init commands run by the WorkspaceStore do not cause the provider plugins to be downloaded. Instead, they rely on a local plugin cache and effectively the provider plugins are installed in workspace folders as symbolic links to the plugin binary in this cache. This makes initialization of a new workspace a relatively cheap operation.
Another important step during workspace initialization by WorkspaceStore is the initialization of a terraform.Workspace struct. A Workspace abstracts the Terraform CLI operations that Terrajet can run in a workspace, such as an apply or a destroy. The WorkspaceStore instance manages an in-memory map from Kubernetes resource UIDs to Workspaces. The ExternalConnecter initializes the ExternalClient it returns for a given Terraformed resource with the corresponding Workspace instance from the WorkspaceStore’s map. This Workspace instance is then used by the ExternalClient to perform synchronous and asynchronous Terraform CLI CRUD operations in the corresponding workspace. More about these operations later!
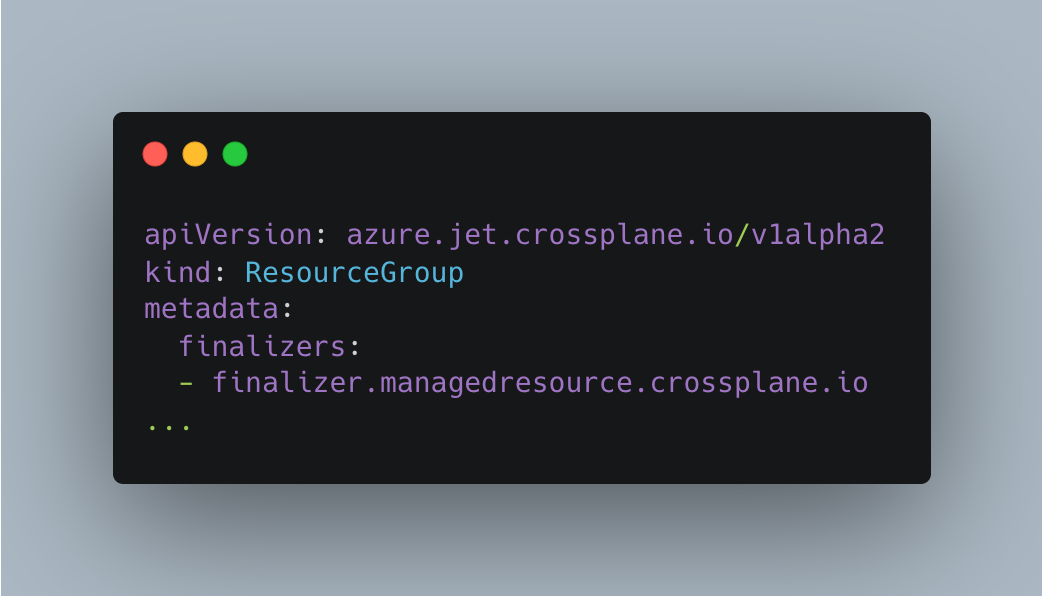
One final point in the context of Terraform workspace lifecycle management is the destruction of a workspace folder via the WorkspaceStore’s terraform.StoreCleaner implementation. Each Terraformed resource installs a resource.Finalizer for the managed reconciler. This finalizer embodies a resource.APIFinalizer to add and remove a Kubernetes finalizer to/from the Terraformed resource (see Fig. 5 below). When a Terraformed resource is being deleted, the managed reconciler invokes this resource.Finalizer’s RemoveFinalizer method to do the cleanup. And the terraform.WorkspaceFinalizer uses its StoreCleaner instance to destroy the Terraform workspace. WorkspaceStore also removes the corresponding terraform.Workspace entry from its map. This effectively ensures that before a Terraformed resource is deleted, the corresponding Terraform workspace is also destroyed.
Generating the Main Configuration and Reconstructing the State Snapshots
For a given Terraformed resource, terraform.FileProducer is responsible for generating the main configuration file in JSON syntax and for generating the state snapshot if it does not already exist in a workspace. As discussed above, WorkspaceStore uses a FileProducer to initialize the workspace folder during a reconciliation loop. Now, we would like to discuss a bit more about how the configuration file (main.tf.json) is generated, and how a state snapshot (terraform.tfstate) is reconstructed.
Generating the main configuration file
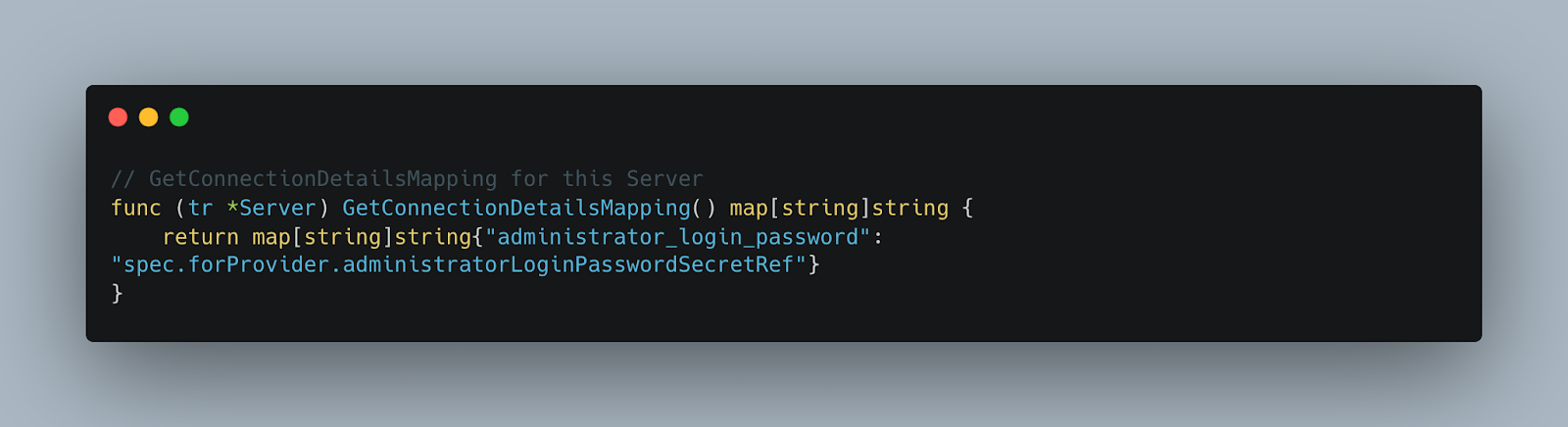
Terrajet uses the jsoniter library to serialize the spec.forProvider of a Terraformed resource using its tf tags (see Fig. 2 above). As discussed in Part 2 of this series, sensitive parameter values that are part of the configuration cannot be stored in spec.forProvider directly but instead, are stored in Kubernetes secrets and are referenced from spec.forProvider as v1.SecretKeySelectors. Terrajet runtime then reads the mapping between the Terraform attribute names and these referencer field names to extract the sensitive data from the referenced secrets and append them to the generated configuration. In Fig. 6 below, we see such a generated mapping between Terraform attribute names and spec.forProvider fields. As discussed in Part 1 of the series, Terrajet automatically generates such mappings for sensitive fields marked as such in the Terraform schema.
One caveat is that we may want to remove certain Terraform attributes from spec.forProvider to make the resource API XRM-compliant. One such common case is where we remove a required identifier argument during code generation, such as the name attribute, from spec.forProvider because XRM uses the external-name annotation to name the resource, and a separate name field under spec.forProvider would duplicate it. This implies that when we serialize spec.forProvider using tf tags, the required name attribute will be missing in the generated configuration. To accommodate this, Terrajet uses the resource configuration discussed in Part 1 to reinject such fields.
After the prevent_destroy meta-argument (see “Terraform Configuration” above) and, if configured, timeouts are injected into the configuration, the JSON document is saved as main.tf.json under the workspace folder.
Generating the state snapshot file
WorkspaceStore generates a state snapshot file (terraform.tfstate) if one does not already exist in the workspace folder using the FileProducer. In order to generate the state snapshot, first the spec.forProvider and then the status.atProvider are serialized using their tf tags. Using the supplied resource configuration, the value for the id attribute is injected. The id attribute is the persistent identifier that uniquely identifies the remote resource. Sensitive input arguments are read and injected from their respective secrets. As we will discuss shortly, Terrajet allows resource specific configuration to be given, which dictates how the persistent identifier will be calculated out of the external-name, arguments and the provider configuration. One final location worth mentioning where state data is stored by Terrajet is the terrajet.crossplane.io/provider-meta annotation. Value of this annotation, if it exists, becomes the private attribute of the Terraform state snapshot.
Finally, the assembled state data is serialized via the json.StateV4 struct into a terraform.tfstate file again in JSON format under the workspace directory.
Resource Specific External-Name and Persistent Identifier Configuration
Terrajet allows resource specific configuration to specify how the external-name and the persistent identifier for a Terraformed resource will be calculated. Two commonly used configuration options are supplied in Terrajet: config.NameAsIdentifier and config.IdentifierFromProvider.
NameAsIdentifier is intended for resources for which the persistent identifier is the resource’s external-name and removes the name Terraform attribute if it exists, from spec.forProvider for XRM-conformance.
IdentifierFromProvider disables the default external-name initializer to set the external-name annotation from the value of the persistent identifier reported by Terraform in the state snapshot. It’s intended to be used with resources whose persistent identifiers are generated by the Cloud provider.
Apart from these common options, the config.ExternalName configuration struct allows us to override:
- ExternalName.GetExternalNameFn: How the external-name for a resource is calculated from state data (in most cases from its persistent identifier) as reported by Terraform in the state snapshot. See this as an example. The specified function is invoked by the Terraformed ExternalClient during the Observe and Create calls with the fresh state returned by Terraform.
- ExternalName.GetIDFn: How the persistent identifier for a resource is calculated as a function of its external-name, spec.forProvider and the associated provider configuration. See this as an example. The persistent identifier calculated with this function is injected into the generated state snapshot if one does not already exist in the workspace folder.
- ExternalName.SetIdentifierArgumentFn: Sets a required naming attribute for a resource. In most cases, the naming attribute is called name, and as discussed previously, it’s removed from spec.forProvider for XRM-conformance.
- ExternalName.DisableNameInitializer: If set, disables the default external-name initializer in cases metadata.name is not used as the external name.
- ExternalName.OmittedFields: Specifies a list of Terraform attributes to be excluded from spec.forProvider during code generation.
Fig. 7 is a schematic representation of these configuration options and is reproduced from here:
{kind=link}

CRUD with Terraform - terraform.Workspace
terraform.Workspace abstracts synchronous and asynchronous Terraform CLI operations in a workspace:
- Workspace.Refresh is called by the ExternalClient’s Observe method and is a synchronous operation. It is basically a terraform apply -refresh-only to have Terraform observe the remote resource and update the state snapshot stored in the workspace.
- Workspace.Plan is called by the ExternalClient’s Observe method and is a synchronous operation. As explained in Part 2 of this series, if the remote resource exists, Plan is invoked to detect drifts between the desired state and the observed state.
- Workspace.Apply and Workspace.ApplyAsync are called by ExternalClient’s Create and Update methods to apply the desired state of the remote resource, and they both invoke terraform apply. Apply is executed synchronously, i.e., the caller is blocked until the terraform apply operation completes. ApplyAsync is the asynchronous version of Apply, and the caller is not blocked by the underlying Terraform CLI operation. If an async operation is in progress during subsequent reconciliations, Terrajet runtime first needs to wait for that operation to complete (either successfully or with failure) and skips that loop before a new one can be initiated.
- Workspace.Destroy and Workspace.DestroyAsync are called by ExternalClient’s Delete method to destroy the remote resource, and they both invoke a terraform destroy. Again, DestroyAsync is the async version, which does not block its caller.
The resource configuration has the UseAsync option that makes the ExternalClient use the asynchronous variants ApplyAsync and DestroyAsync. If this option is not set, their synchronous variants are used. The UseAsync option is meant to be used for resources whose provisioning or de-provisioning takes a long time, and would not be completed in the context of a single reconciliation loop. When ApplyAsync or DestroyAsync is called, the Terraform CLI is forked by a separate goroutine and that goroutine executing the Terraform command waits for the child process to exit. The results of this execution (success/failure, errors encountered, etc.) are then reported by this goroutine in an asynchronous way by updating the status of the corresponding Terraformed resource.
At any given time, at most one Terraform CLI operation can be running in a workspace. Workspace has the notion of a LastOperation, which tracks the last async operation invoked in the workspace. When an asynchronous operation completes, it marks its Workspace’s LastOperation as finished, so that a new operation can be started by the ExternalClient.
Packaging Terrajet-based Providers
When WorkspaceStore is initializing a new Terraform workspace, it runs a terraform init to have the native provider plugin installed into the workspace. In its default mode, Terraform inspects the configuration and downloads the required provider plugins into the workspace’s .terraform folder. However, this is not feasible in Terrajet’s use cases:
- Terrajet runtime manages multiple resources and their corresponding workspaces, possibly thousands of them. Having to download the plugin binary for each workspace is not feasible.
- The Terrajet-based provider could be running in an air-gap environment with no access to the plugin repo.
For such reasons, Terrajet-based providers download and install their associated provider plugin binary at a designated path on the image filesystems. For instance, provider-jet-azure:
- Places the terraform-provider-azurerm native provider plugin under a subdirectory of /terraform/provider-mirror,
- And configures the Terraform CLI, via the TF_CLI_CONFIG_FILE environment variable pointing to the path of the .terraformrc given in Fig. 8, so that Terraform CLI uses that directory as the binary plugin cache.

Concluding Remarks
And here we are, concluding a highly technical blogpost series of three parts introducing Terrajet! Come and join us in generating new Terraform-backed providers with ease using Terrajet. Please also join us in the Crossplane slack for questions, support, to share ideas, or just to say a hello :)